本文共 2591 字,大约阅读时间需要 8 分钟。
(八)分类数据分析
首先思考问题:
1. 为什么要对数据进行分类?如何对数据分类?
2. 数据分类后,如何对分类数据进行分析?
数据分类

- 你吸烟吗? 1.是;2.否
- 你赞成还是反对这一改革方案? 1.赞成;2.反对
对分类数据的描述和分析通常使用列联表
可使用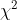 统计量
统计量
可以用于测定两个分类变量之间的相关程度。若用
表示观察值频数(observed frequency),用
表示期望值频数(expected frequency),则
统计量可以写为:
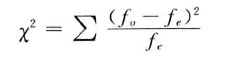
统计量有如下特征:首先
,因为它是对平方结果的汇总;其次,
统计量的分布与自由度有关;最后,
统计量描述了观察值与期望值的接近程度。两者越接近,即
越小,计算出的
值就越小;反之,
越大,计算出的
值也越大。
检验正是通过对
的计算结果与
分布中的临界值进行比较,作出是否拒绝原假设的统计决策。

分布与自由度的关系如上图所示。上图中显示了自由度分别为 1,5 和 10 时相应的
分布。
自由度越小,分布就越像左边倾斜,随着自由度的增加,分布的偏斜度趋于缓解,逐渐显露出对称性,随着自由度继续增大,
分布将趋近于对称的正态分布。
利用统计量,可以对分类数据进行拟合优度检验和独立性检验。
拟合优度检验
拟合优度检验是用统计量进行统计显著性检验的重要内容之一。它是依据总体分析状况,计算出分类变量中各类别的期望频数,与分布的观察频数进行比较,判断期望频数与观察频数是否有显著差异,从而达到对分类变量进行分析的目的。
列联分析:独立性检验
对两个分类变量的分析,称为独立性检验,分布过程可以通过列联表的方式呈现,故有人把这种分析称为列联分析。
列联表:是将两个以上的变量进行交叉分类的频数分布表。由于列联表中的每个变量都可以有两个或两个以上的类别,列联表会有多种形式。不妨将横向变量(行)的华分类别视为R,纵向变量(列)的划分类别视为C,这样可以把每一个具体的列联表称为列联表。
下面是 的列联表

下表是称为 列联表。

表中的行(row)是产地变量,这里划分为三类:甲、乙、丙三个地区。表中的列(column)是产品等级变量,这里也划分为三类:一级品、二级品、三级品。因此上表是一个 列联表,表中的每个数据都反映了产地和产品等级两个方面的信息。
独立性检验就是分析列联表中行变量和列变量是否互相独立。
例题:
一种原材料来自三个不同的地区,原料质量被分成三个不同等级。从这批原料中随机抽取500件进行检验,结果如上表所示,要求检验各个地区和原料等级之间是否存在依赖关系。()
求解:
:地区和原料等级之间是独立的(不存在依赖关系)
:地区和原料等级之间不独立(存在依赖关系)
这里分析的关键是获得期望值。
在表中第一行,甲地区的合计为 140,用 140/500 作为甲地区原料比例的估计值。
在表中第一列,一级原料的合计为 162,用 162/500 作为一级原料比例的估计值。
如果地区和原料等级之间是独立的,则可以用下面的公式估计第一个单元(甲地区,一级)中的期望比例。
令: 样本单位来自甲地区的事件
样本单位属于一级原料的事件
根据独立性的概率乘法公式,第一个单元格记作:
0.09072 是第一个单元中的期望比例,相应的频数期望值为:
一般地,可以采用下面式子计算任何一个单元中频数的期望值:
式子中, 为给定单元中的频数期望值;RT为给定单元所在行的合计;CT为给定单元所在列的合计;n为观察值得总个数,即样本量。
根据上面表格中的数据,进行计算:
| 行 | 列 | |||||
|---|---|---|---|---|---|---|
| 1 | 1 | 52 | 45.36 | 6.64 | 44.09 | 0.97 |
| 1 | 2 | 64 | 52.64 | 11.36 | 129.05 | 2.45 |
| 1 | 3 | 24 | 42.00 | -18.00 | 324.00 | 7.71 |
| 2 | 1 | 60 | 55.40 | 4.60 | 21.16 | 0.38 |
| 2 | 2 | 59 | 64.30 | -5.30 | 28.09 | 0.44 |
| 2 | 3 | 52 | 51.30 | 0.70 | 0.49 | 0.01 |
| 3 | 1 | 50 | 61.24 | -11.24 | 126.34 | 2.06 |
| 3 | 2 | 65 | 71.06 | -6.06 | 36.72 | 0.52 |
| 3 | 3 | 74 | 56.70 | 17.30 | 299.29 | 5.28 |
| 19.82 | ||||||
的自由度为:
令:,查表知:
由于 ,故拒绝
,接受
,即地区和原料等级之间存在依赖关系,原料的质量受地区的影响。
注意:自由度的计算说明:
计算公式为: 自由度 = (行数-1)(列数-1)=(R-1)(C-1)
检验中自由度计算的原理。自由度是可以自由取值的数据的个数,采用自由度 = (行数 -1)(列数 -1)= (R-1)(C-1)公式计算。这样做的原因可以通过下面例子说明。
假设我们有一个 列联表
| C1 | C2 | C3 | C4 | 合计 | |
| R1 | √ | √ | √ | * | |
| R2 | √ | √ | √ | * | |
| R3 | * | * | * | 0 | |
| 合计 |
说明:
- √ 表示可以自由取值的数据
- * 和0 表示不能自由取值的数据
首先看这个表中的第一行,在行合计 已经确定的情况下,这一行可以自由取值的数据只有3个(这里假定取前3个),用 √ 表示,最后一个无法自由取值,用 * 表示;类似的,在第二行,在行合计
已经确定的情况下,这一行可以自由取值的数据也只有3个,因此第4个不能自由取值的数据也用 * 表示。在第三行,第一个数据(R3,C1)不能自由取值,同理,第三行的第二和第三个数据也不能自由取值,因此这一行的前三个数据均用 * 表示。第三行的第四个数据也不能自由取值,用 0 表示,因为不论从行或列来看,它前面的数据均是无法自由取值的(意味着该值已经确定),在行、列合计确定的情况下,这个值也就无法自由选取。上表是一个
列联表,自由度为 6 ,即:
自由度 = (R-1)(C-1)=(3-1)(4-1)= 6
列联表中的相关测量
对两个变量之间相关程度的测定,主要用相关系数表示。列联表中的变量通常是类别变量,它们所表现的是研究对象的不同品质类别。所以,可以把这种分类数据之间的相关称为品质相关。经常用到的品质相关系数有以下几种:
相关系数
列联相关系数
V 相关系数
数值分析
列联分析中应注意的问题
条件百分表的方向
分布的期望值准则
(更新中)
转载地址:http://kvvdi.baihongyu.com/